⚡ Performance and Efficiency Benchmarks
This section reports the performance on NPU with FastFlowLM (FLM).
Note:
- Results are based on FastFlowLM v0.9.30.
- Under FLM’s default NPU power mode (Performance)
- Newer versions may deliver improved performance.
- Fine-tuned models show performance comparable to their base models (e.g., LFM2-1.2B vs. LFM2.5-Instruct-1.2B/LFM2.5-Thinking-1.2B, and LFM2-2.6B vs. LFM2-2.6B-Transcript).
Test System 1:
AMD Ryzen™ AI 7 350 (Kraken Point) with 32 GB DRAM; performance is comparable to other Kraken Point systems.
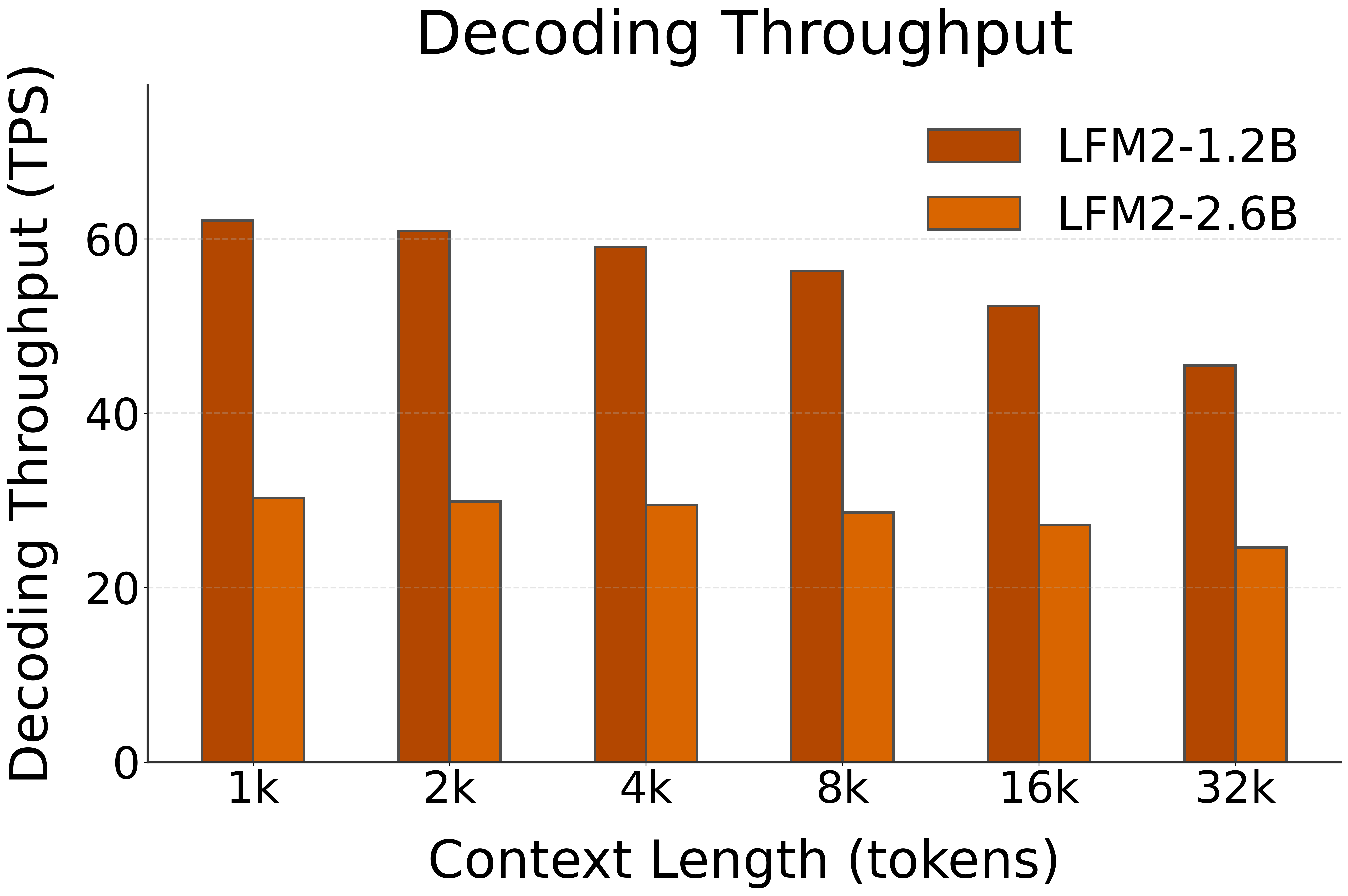
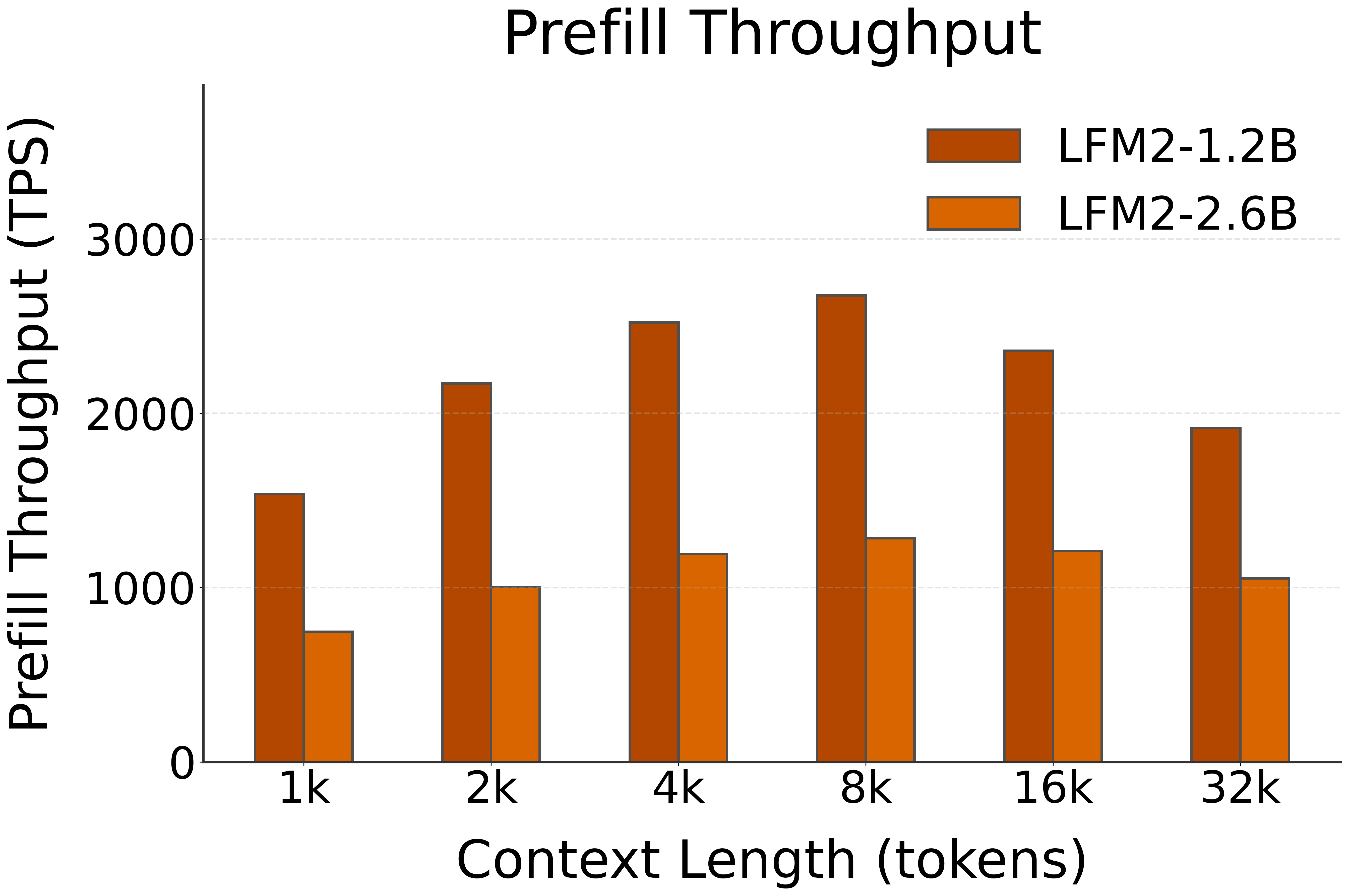
🚀 Decoding Speed (TPS, or Tokens per Second, starting @ different context lengths)
| Model | HW | 1k | 2k | 4k | 8k | 16k | 32k |
|---|---|---|---|---|---|---|---|
| LFM2-1.2B | NPU (FLM) | 62 | 61 | 59 | 56 | 52 | 46 |
| LFM2-2.6B | NPU (FLM) | 30 | 30 | 30 | 29 | 27 | 25 |
🚀 Prefill Speed (TPS, or Tokens per Second, with different prompt lengths)
| Model | HW | 1k | 2k | 4k | 8k | 16k | 32k |
|---|---|---|---|---|---|---|---|
| LFM2-1.2B | NPU (FLM) | 1537 | 2172 | 2521 | 2677 | 2359 | 1916 |
| LFM2-2.6B | NPU (FLM) | 747 | 1004 | 1193 | 1284 | 1210 | 1053 |
Test System 2:
AMD Ryzen™ AI 9 370 (Strix Point) with 32 GB DRAM; performance is comparable to other Strix Point and Strix Halo Point systems.
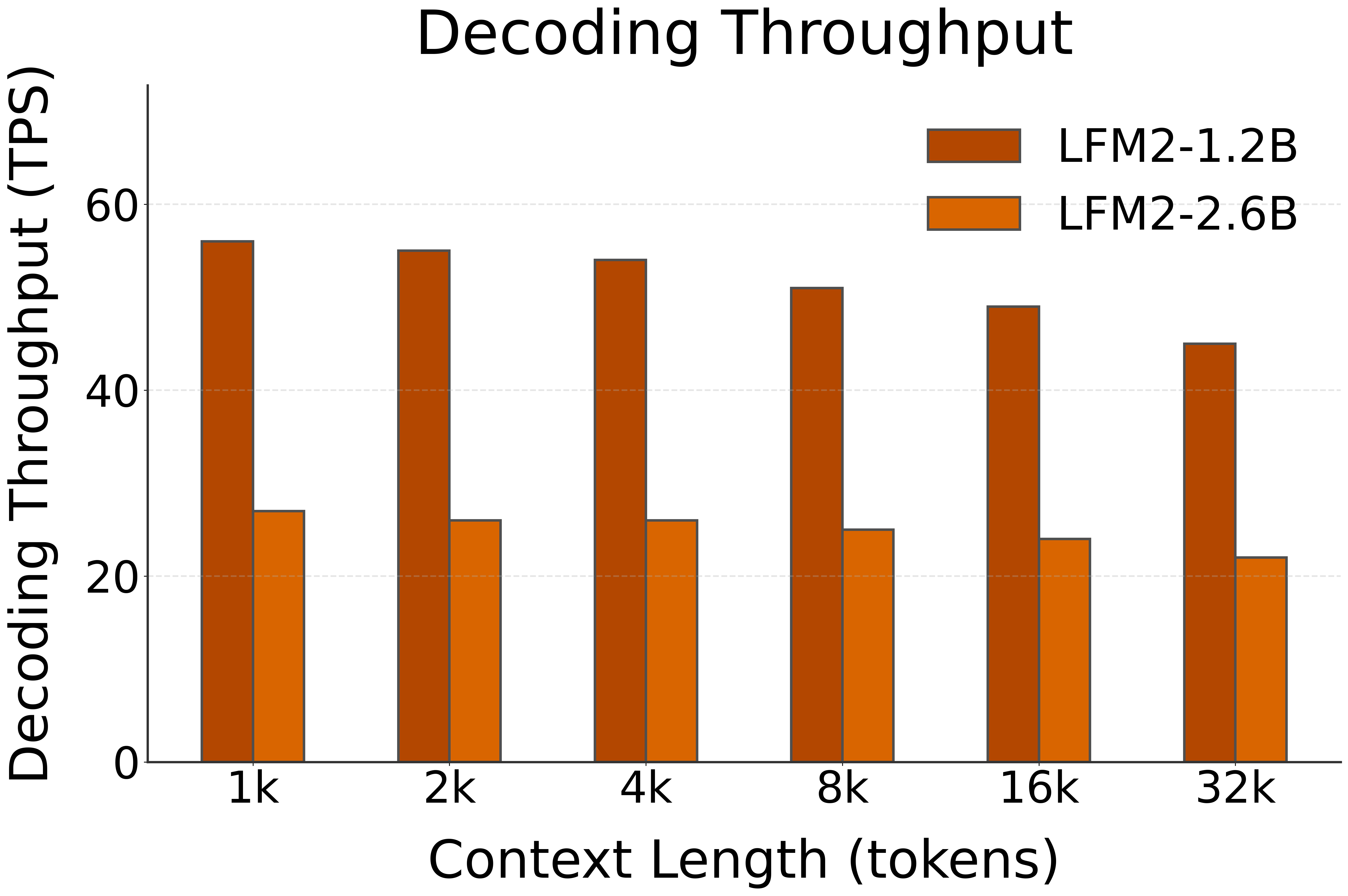
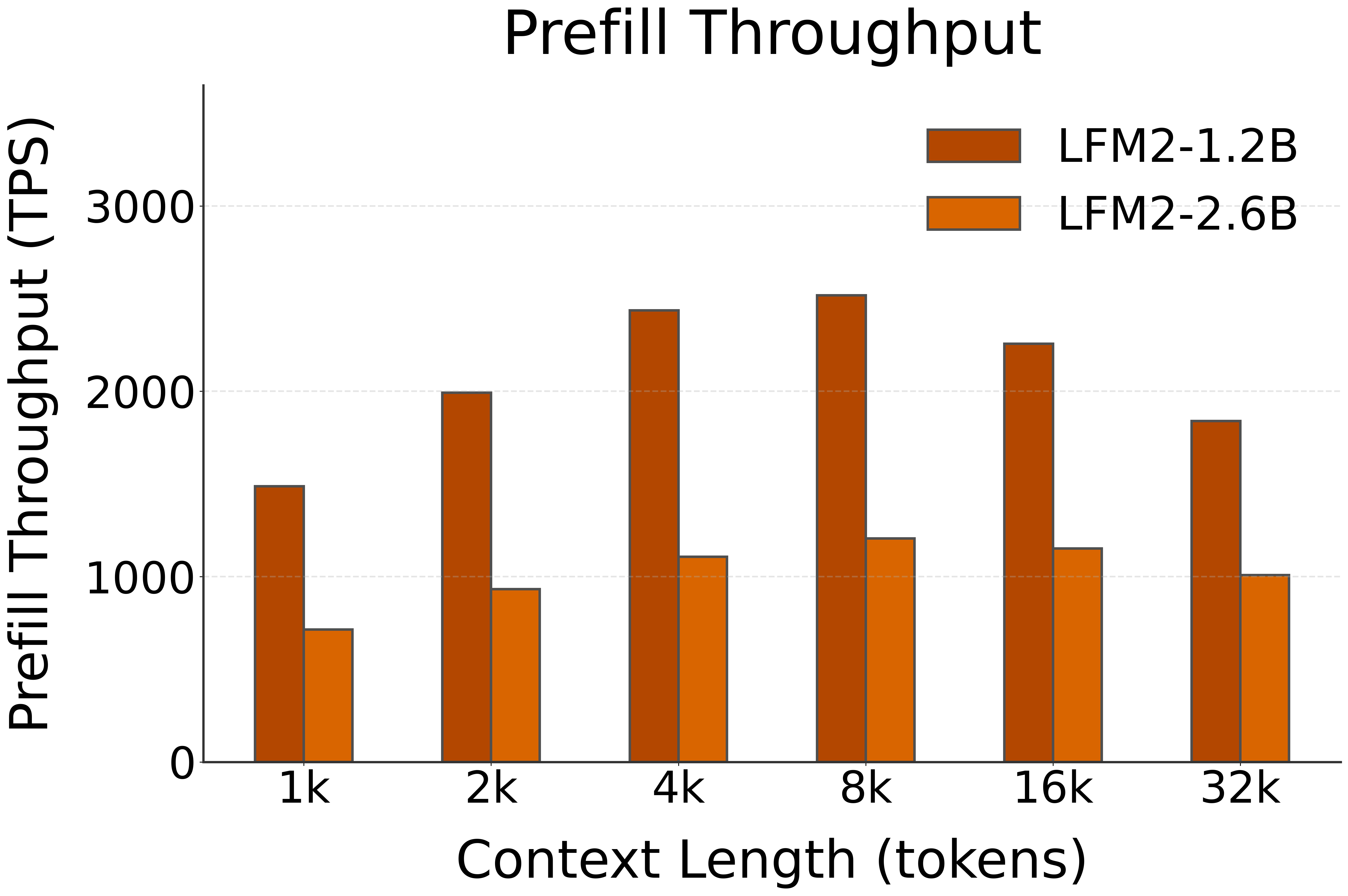
🚀 Decoding Speed (TPS, or Tokens per Second, starting @ different context lengths)
| Model | HW | 1k | 2k | 4k | 8k | 16k | 32k |
|---|---|---|---|---|---|---|---|
| LFM2-1.2B | NPU (FLM) | 56 | 55 | 54 | 51 | 49 | 45 |
| LFM2-2.6B | NPU (FLM) | 27 | 26 | 26 | 25 | 24 | 22 |
🚀 Prefill Speed (TPS, or Tokens per Second, with different prompt lengths)
| Model | HW | 1k | 2k | 4k | 8k | 16k | 32k |
|---|---|---|---|---|---|---|---|
| LFM2-1.2B | NPU (FLM) | 1487 | 1992 | 2436 | 2518 | 2257 | 1839 |
| LFM2-2.6B | NPU (FLM) | 715 | 932 | 1107 | 1206 | 1152 | 1008 |