⚡ Performance and Efficiency Benchmarks
This section reports the performance of LLaMA 3.x on NPU with FastFlowLM (FLM).
Note:
- Results are based on FastFlowLM v0.9.30.
- Under FLM’s default NPU power mode (Performance)
- Newer versions may deliver improved performance.
- Fine-tuned models show performance comparable to their base models.
Test System 1:
AMD Ryzen™ AI 7 350 (Kraken Point) with 32 GB DRAM; performance is comparable to other Kraken Point systems.
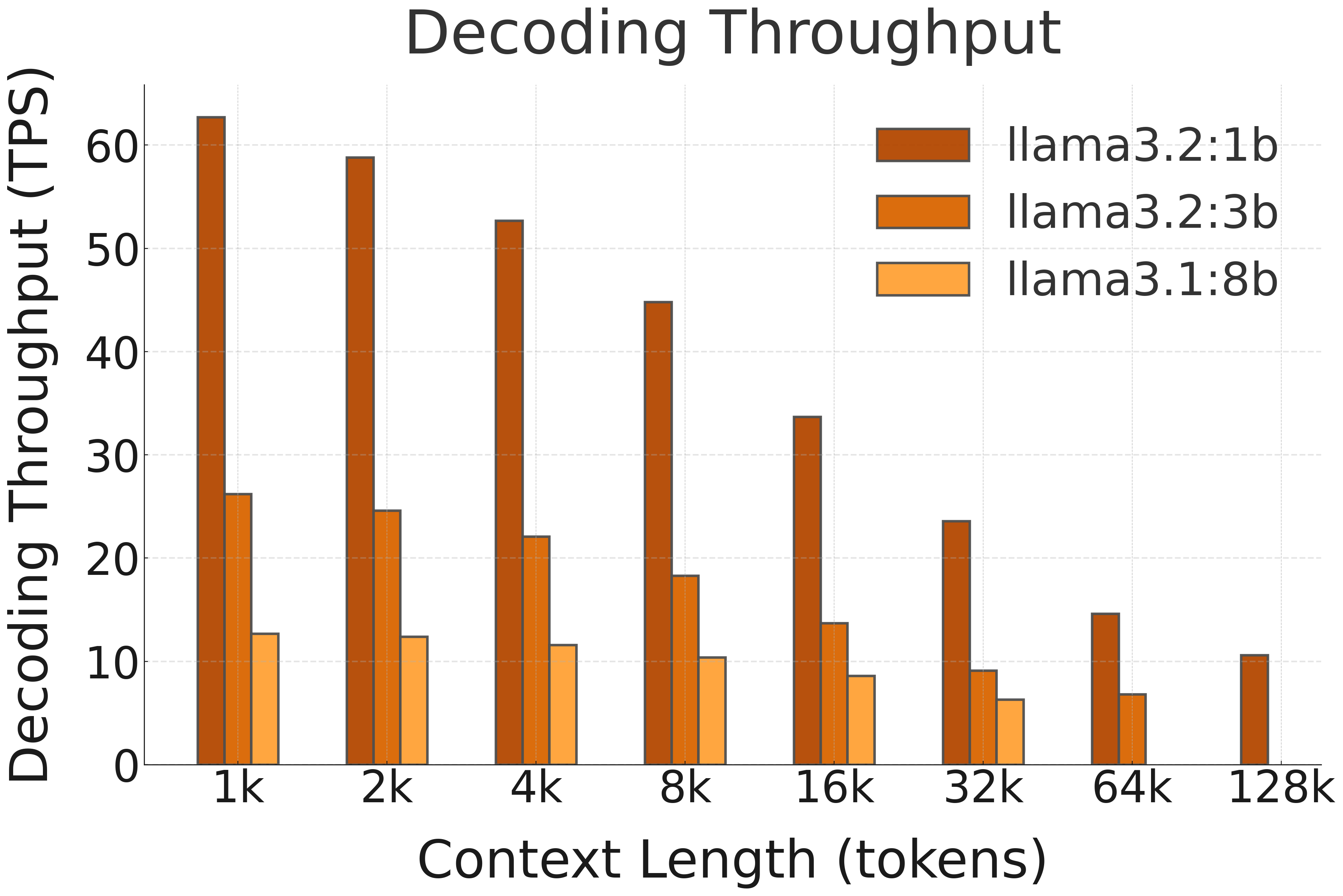
🚀 Decoding Speed (TPS, or Tokens per Second, starting @ different context lengths)
| Model | HW | 1k | 2k | 4k | 8k | 16k | 32k | 64k | 128k |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA 3.2 1B | NPU (FLM) | 64.5 | 62.2 | 58.9 | 53.9 | 45.5 | 35.0 | 24.1 | 13.6 |
| LLaMA 3.2 3B | NPU (FLM) | 26.3 | 25.5 | 24.1 | 21.7 | 18.0 | 13.6 | 9.0 | OOM |
| LLaMA 3.1 8B | NPU (FLM) | 12.8 | 12.6 | 12.2 | 11.5 | 10.2 | 8.5 | OOM | OOM |
OOM: Out Of Memory
Only <50% system DRAM can be accessed by NPU
On systems with more than 32 GB DRAM, longer context lengths are supported. FLM supports the full context length available for each model.
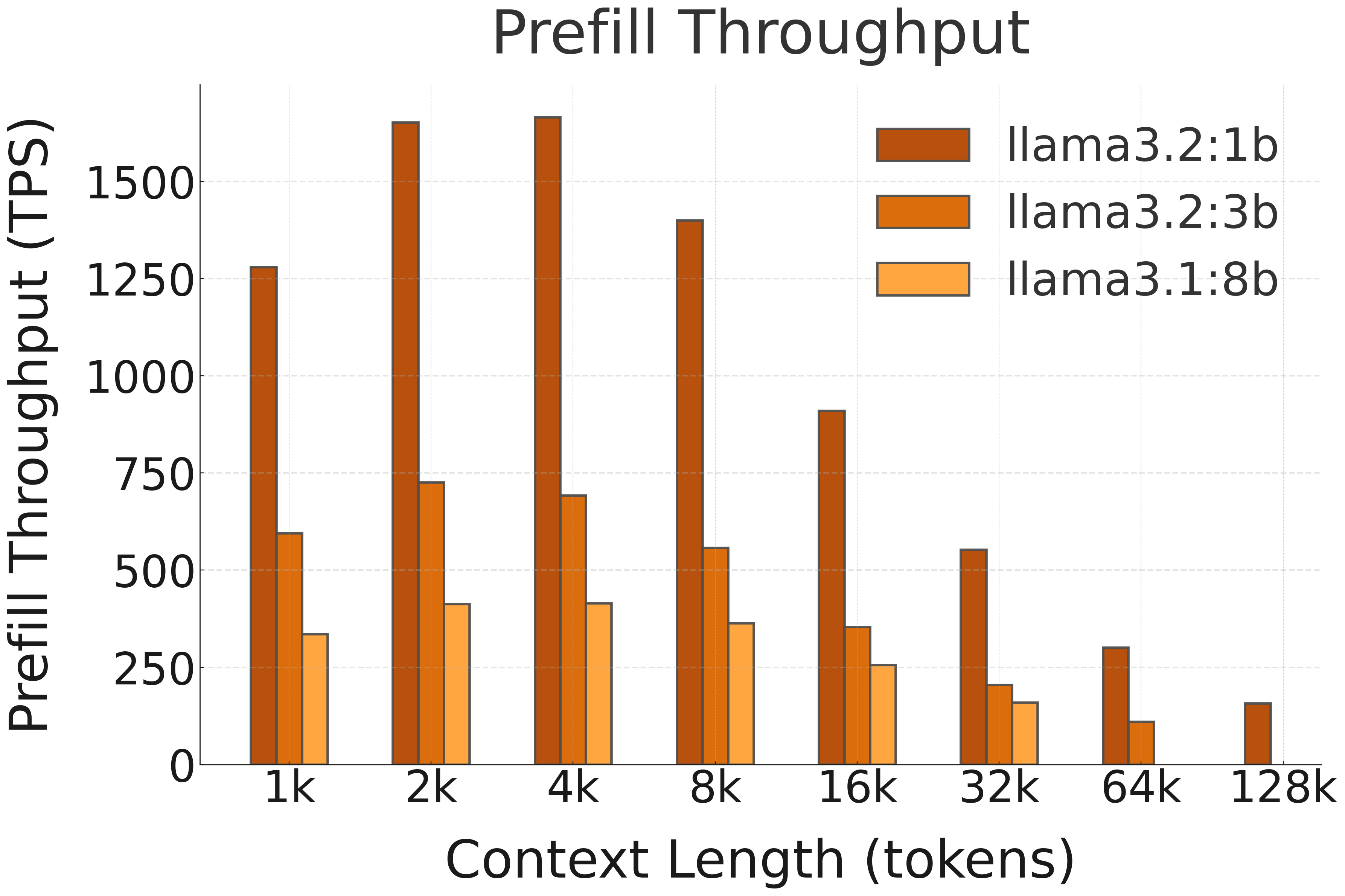
🚀 Prefill Speed (TPS, or Tokens per Second, with different prompt lengths)
| Model | HW | 1k | 2k | 4k | 8k | 16k | 32k |
|---|---|---|---|---|---|---|---|
| LLaMA 3.2 1B | NPU (FLM) | 1686 | 2136 | 2339 | 2212 | 1706 | 1157 |
| LLaMA 3.2 3B | NPU (FLM) | 766 | 910 | 991 | 933 | 721 | 500 |
| LLaMA 3.1 8B | NPU (FLM) | 403 | 472 | 495 | 467 | 381 | 281 |