⚡ Performance and Efficiency Benchmarks
This section reports the performance on NPU with FastFlowLM (FLM).
Note:
- Results are based on FastFlowLM v0.9.30.
- Under FLM’s default NPU power mode (Performance)
- Newer versions may deliver improved performance.
- Fine-tuned models show performance comparable to their base models.
Test System 1:
AMD Ryzen™ AI 7 350 (Kraken Point) with 32 GB DRAM; performance is comparable to other Kraken Point systems.
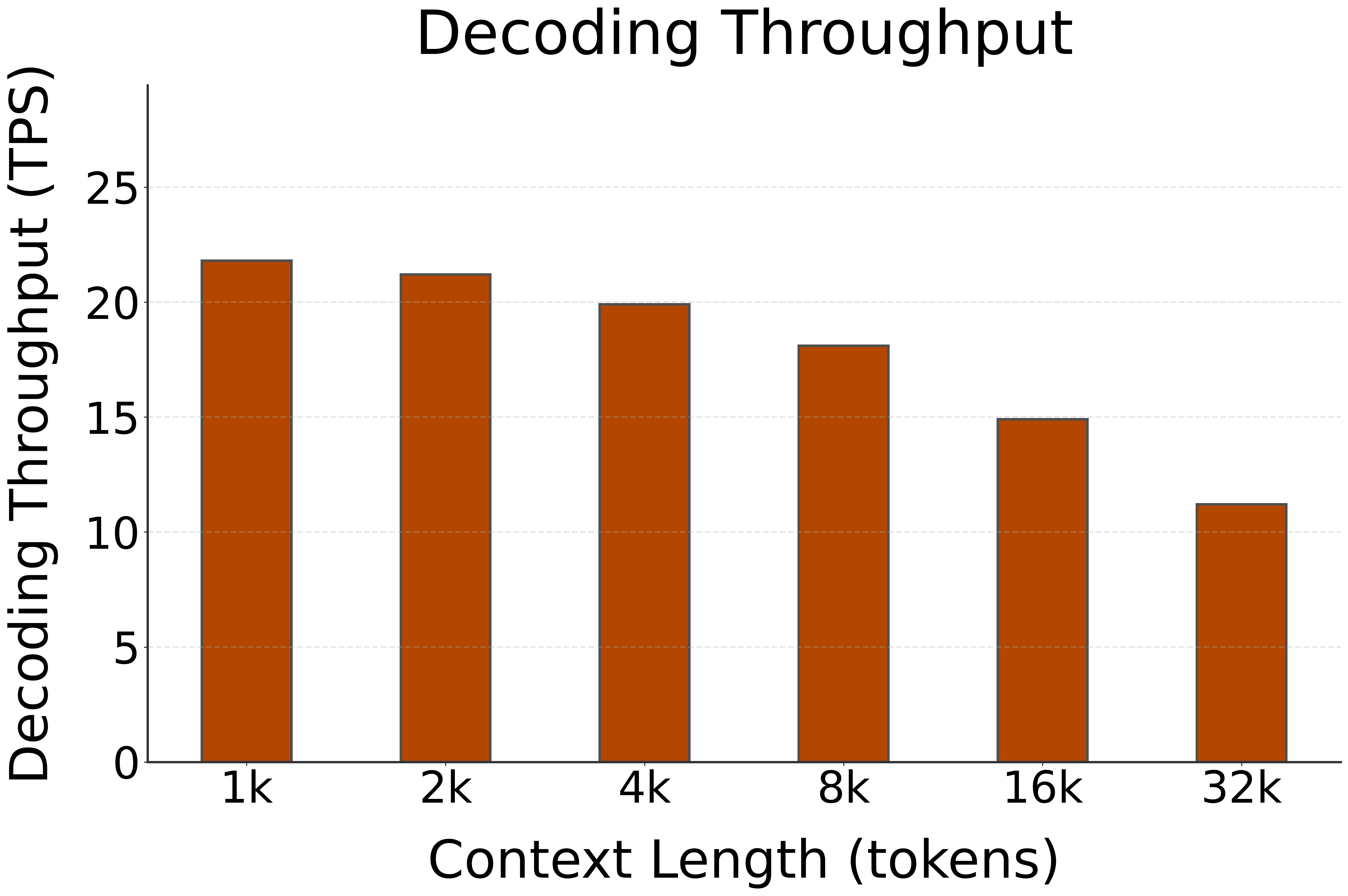
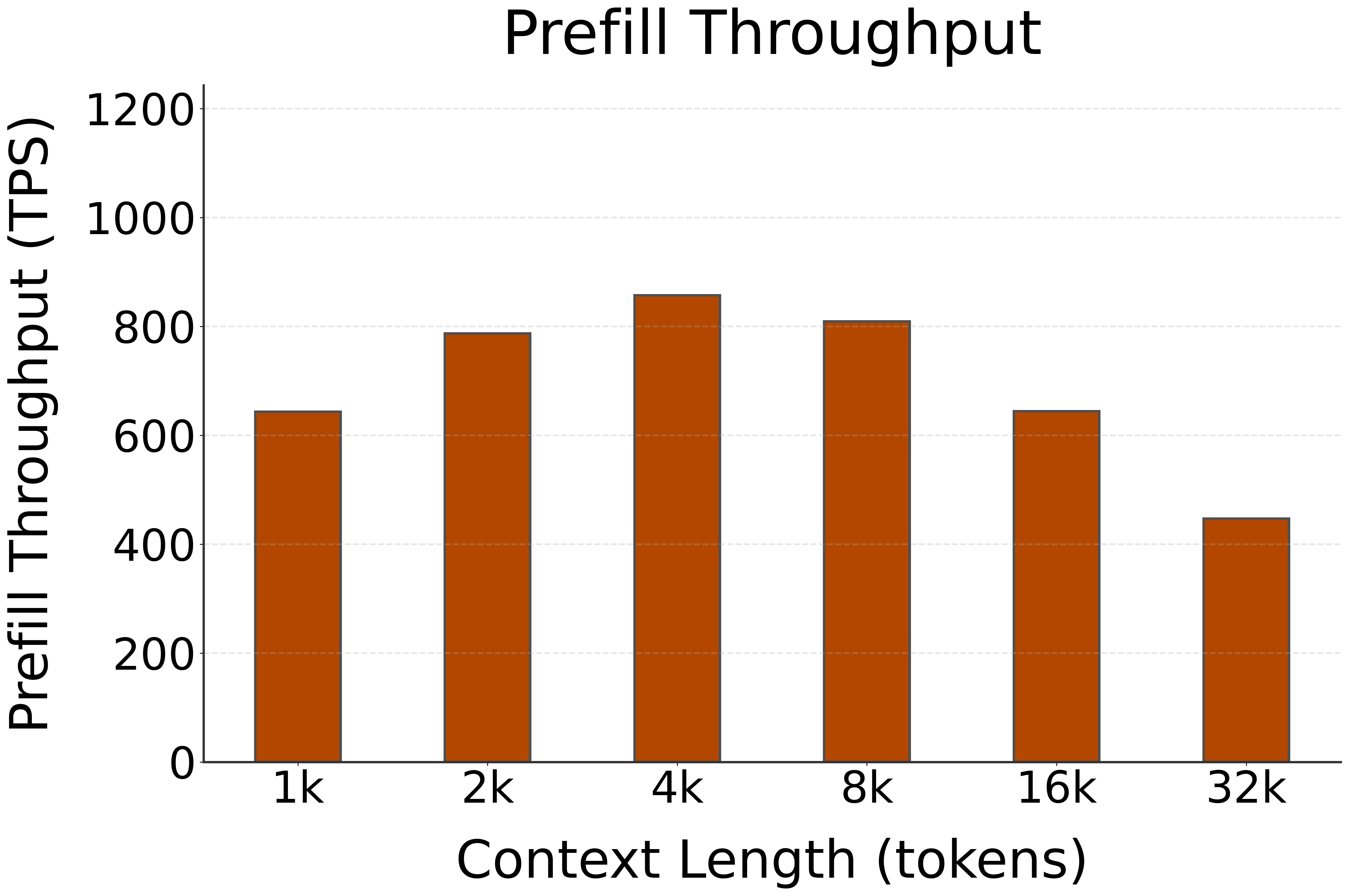
🚀 Decoding Speed (TPS, or Tokens per Second, starting @ different context lengths)
| Model | HW | 1k | 2k | 4k | 8k | 16k | 32k |
|---|---|---|---|---|---|---|---|
| Phi-4-mini-instruct | NPU (FLM) | 21.8 | 21.2 | 19.9 | 18.1 | 14.9 | 11.2 |
🚀 Prefill Speed (TPS, or Tokens per Second, with different prompt lengths)
| Model | HW | 1k | 2k | 4k | 8k | 16k | 32k |
|---|---|---|---|---|---|---|---|
| Phi-4-mini-instruct | NPU (FLM) | 643 | 787 | 857 | 809 | 644 | 447 |